

校园一卡通系统挖掘学生异常行为浅析
文章出处:http://www.nexussmartsolutions.com 作者:吴慧韫 王河堂 人气: 发表时间:2011年07月09日
当前,在高校扩招和学生队伍总量不断增大的背景下,高校学生异常行为的人数呈上升趋势,一些违法、违纪、违俗、违德等异常行为时有发生,而学生管理工作者也往往因为学生异常行为发生前的“苗头”把握不准,常常处于当“消防员”的被动局面。
如何利用现代化的手段对学生早期异常行为进行检测与控制,帮助管理者及时发现有问题的学生,从而进行有针对性的教育与帮助,具有十分重要的意义。
一卡通数据来源
近年来,随着计算机网络和数据库技术的日渐完善,国内不少大学都相继建立了校园一卡通系统。校园一卡通系统是数字化校园的重要组成部分,它为数字化校园的建设提供了全面的数据采集和良好的信息共享环境。
该系统的开发建设将进一步提高信息化管理水平,实现由面向计算机的管理转变为面向数据管理。而目前大多数高校仅仅停留在使用一卡通系统的基础上,殊不知可在此基础上建立数据仓库系统,实现对各部门生成的大量数据的科学提取、净化、存储,从而使得信息系统满足从业务处理到中层管理的控制,以及通过对各阶段各部门的数据进行统计、分析、挖掘,最终达到为领导决策提供支持的目的。
校园一卡通系统一旦建成,它所采用的校园卡可替代现有的多种证件,包括:学生证、工作证、身份证、借书证、阅览证、医疗证、会员证、就餐卡和钱包等。
校园一卡通系统的主要数据来源:
1.学生入校时填写的各种登记表格、各学期注册情况登记等相关文档。
2.学生在食堂就餐时的划卡记录。
3.学生体检情况、就医情况的医疗记录。
4.图书馆学生借书情况登记、进出图书馆闸机记录等。
5.校内各种开放设施的划卡消费情况记录,如公共机房、校体育设施、校宾馆饭店。
6.学生早锻炼情况的记录。
7.学生通过门禁系统出入各建筑楼宇的记录。
这些数据均可以从数字化校园中的公共数据平台及相关职能部门的信息管理系统中导出、汇总进入数据仓库。
利用数据挖掘异常行为
数据的条件独立性
一般说来,数据的独立性包括条件独立性、因果独立性与上下文独立性。这些独立性关系,都对数据分析具有重要的作用。
条件独立性是指在某些变量给定时,其他部分结点相独立,因此只要找出特定的给定变量,即可为决策提供足够的支持,这称为条件独立性。因果独立性是指变量之间的直接影响,但是并没有对如何依赖作出约束。一些情况下,多个变量相互合作,对某变量共同产生影响。但是,很多情况下,各变量独自对其他变量起作用,原因变量之间没有合作,此时原因变量对结果变量的影响是因果独立的,这称为因果独立性。
通常每个变量都带有条件概率标,在各原因变量状态组合的每种取值情况下给出结果变量的每种取值的条件概率。条件概率表一方面需要的条件概率数目是原因变量结点数目的指数幂,另一方面无法捕捉原因变量概率分布的某些规律。这是第三种独立关系,称为上下文独立性,通常可以采用条件概率树的形式对上下文独立关系进行表示。本文以条件独立性为例,对一卡通的数据信息进行研究。
一般地,若变量E和F在G给定(p(G)≠0)时,满足下列条件之一时是条件独立的:
1. P(E|F∩G)=P(E|G) 且 P(E|G)≠0,P(F|G)≠0
2.P(E|G)=0 或 P(F|G)=0
基于条件独立性的数据分析
为了提高有问题学生认定的准确率与有效性,针对一卡通的相关数据流进行以下几个方面的分析:
1.根据学生入学时填写的各种记录表初步了解其基本情况。
2.通过分析长期的学生的金融消费数据以及楼宇身份认证等数据计算月平均开销、出入教师或图书馆的频率、早锻炼的积极性等,给出认证偏低区间的实证结果。这可用来发现性格内向但不愿向师长和同学说明情况的学生。
3.根据校内各种开放设施的划卡消费及认证情况记录计算月平均开销及各种活动的出勤情况。对于月开销较大或出勤情况反常的学生应深入了解情况,杜绝个别学生思想临时出现紧急波动的情况。
4.根据体检情况、就医情况的医疗记录关注有问题学生的健康状况。对于健康状况较差的有问题学生应加大援助的力度。
5.根据上机情况、图书馆借阅情况及考试成绩了解有问题学生的学习努力程度。
本文针对上述的第二条中的数据进行重点的数据挖掘,同时针对初步结果,再结合第一、三、四、五条进行聚类分析,试图寻找到消费和认证行为的某些相关性及条件独立性,从而有助于学校及早发现思想有问题的学生,为教师进行思想有问题学生决策提供更准确的数据支持。
一卡通信息的数据挖掘
1.数据准备:由于一卡通的流水数据中有许多庞大的价值较低的数据,因此,现有的一卡通流水数据必须经过数据的预处理后才能变成挖掘的对象。
(1)将卡流水交易数据库分割成小的数据表。我们将校园卡流水交易数据库分成若干张细表,每个表为一个月的数据,少则几万(假期),多则上百万条记录。
(2)通过卡号将存在于卡流水交易数据库和用户资料表的数据搜索出来,为数据挖掘提供数据源。
(3)计算属性:由于集成几个数据库而得到的数据依然反映的是每次刷卡交易的记录,实际情况是消费或认证可能在某处的一个或多个POS机上完成。因此需根据刷卡的时间进行分段求和,我们把一天分成三个时间段(0∶00~10∶00,10∶00~15∶00,15∶00~24∶00),在这三个时间段内的刷卡记录分别归为早、中、晚三个阶段,因此对于每一个卡号用户必须分别按这三个时段统计出三个阶段的刷卡频率。
本地学生周末通常不在学校,因此需要特殊处理;考试期间由于学业繁重,早锻炼的频率也将正常下降,此时也需要特殊处理。但为了分析结果的准确性,不能清洗任何刷卡记录。
2.建立数据仓库
采用Microsoft Analysis Services建立数据仓库:首先新建数据仓库DSS,数据源自于上述经过预处理的一卡通数据库;然后建立多维数据集,将所有数据按月划分为多个数据表,每个数据表建立一个多维数据集,选择刷卡金额或认证次数为度量值,通过POS机具信息表、账户信息表、认证信息表建立维度表。
3.知识分析
根据一个月的情况,计算出每个学生的每月学习日的刷卡次数(X)。
这里我们定义以下几个指标:每月学习日正餐消费次数(X)、每月学习日正餐最低消费次数参考值(M)、学习日正餐的一餐消费额(Y)、学习日正餐的一餐消费额参考值(N)。
若满足X≥M,以及Y<N,可认定为是刷卡次数偏低的群体,这个群体组成一个集合。结合该群体的基本信息如生源地、性别、年龄、年级等分析其相关性。
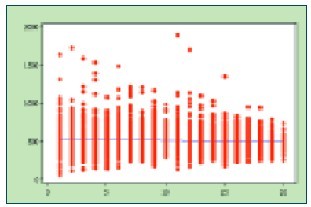
图1 学生正餐消费次数与消费金额分布
图1是学生正餐消费次数与消费金额分布图示例。X轴为某月份(2010年9月份)学生正餐消费次数(除去每日早餐与周六、周日三餐),Y轴为该月正餐的一餐消费均值(单位为分),图1抽样数据为2010级所有学生(4150名)。管理者可以粗略地观察消费均值集中分布区域,与消费次数集中分布区域。如需要进一步挖掘出低消费人群,需要在下文中进一步分析。
M和N是人为给定的,需要校方管理人员结合实情与经验给出,比如上例中,我们假定为M=15次,N=5.00元,则通过X≥15次,N<5.00元,可以找到图1中相应的消费偏低的群体。
以上仅是一种理想的状况,在真实的分析中,有时需要根据不同的聚类来调整参数以得到不同的分析结果。比如:刷卡消费偏低群体中性别比例与实际在校生的性别比差别很大时,可能是学习日男女活动的频率差异参考值导致,因为男女生有较大差异,需要调整。我们抽样的数据可以进一步按性别进行聚类分样。
最后,通过学生基本信息库的关联分析,我们可以进一步得到:刷卡消费偏低与家庭情况的相关性、刷卡次数偏低与校内其他开放设施的划卡消费相关性、刷卡消费偏低与图书馆自习次数的相关性、刷卡消费偏低与就诊次数的相关性等等,以此让教师有更全面的判断。例如对于刷卡消费偏低同时图书馆自习次数较多成绩优秀的学生应给予助学补助及勤工助学机会。
对于刷卡次数异常的学生,说明思想出现了波动,例如经常不参加集体活动或经常在正常上课时间外出等。学校根据分析结果,找出这些行为异常的学生名单,便于校方进行重点的思想教育活动。
数字化校园及一卡通系统中所存储的学生信息、一卡通数据,成为有问题学生的决策依据,这仅是数据挖掘在数字化校园中的一个简单应用,如何把数据挖掘技术和数字化校园更好地结合起来,为高校的管理、建设决策提供更完备的支持是各大高校接下来面临的一个现实问题。








